Рассмотрим случай, когда требуется настроить мониторинг сервера по множеству однотипных или динамических метрик, которые отсутствуют в zabbix-агенте.
В такой ситуации в zabbix-агенте можно создавать ключи для проверки с помощью параметра конфигурации - UserParameter. Для каждого параметра в zabbix_agentd.conf создаётся строка вида:
UserParameter=<key>,<shell command>
Однако, если значений слишком много, такой способ может оказаться не удобным.
Второй способ заключается в использовании элемента данных zabbix типа trapper (zabbix-ловушки). Принцип очень простой: в zabbix-сервере создаются элементы данных этого типа с произвольным именем ключа. Затем, с помощью утилиты zabbix_sender формируется специальный запрос, в котором указывается ключ ловушки, значение параметра и имя хоста. Если параметров много, то можно сформировать файл в формате zabbix_sender и отправить все значения из файла за одно соединение с сервером.
Строки в файле должны быть оформлены в таком виде:
- <ключ> <значение> (дефис в начале строки обязателен)
или
<имя_хоста> <ключ> <значение>
Рассмотрим, как использовать эту возможность на примере мониторинга популярного веб-сервера Nginx. Для этого веб-сервера есть возможнось использовать модуль stub_status, который показывает в цифрах текущую нагрузку на Nginx примерно в таком виде:
Active connections: 26server accepts handled requests1344375 1344375 3208201Reading: 0 Writing: 2 Waiting: 24
Из этих данных мы можем получить, например, такие метрики для мониторинга:
- nginx_status.active - количество всех открытых соединений
- nginx_status.reading - количество запросов, у которых nginx читает заголовки запроса
- nginx_status.writing - количество запросов, у которых в данный момент сервер читает тело запроса, обрабатывает запрос или пишет ответ клиенту
- nginx_status.waiting - количество неактивных(keep-alive) соединений
- nginx_status.accepts - количество принятых запросов в секунду
- nginx_status.handled - количество обрабатываемых запросов в секунду
- nginx_status.requests - количество запросов в секунду
Благодаря этим параметрам можно оценить нагрузку на сервер (в течении дня, недели и т.д.) , а также оценить узкие места в его работе (медленный ли канал у сервера, медленные ли каналы у клиентов, медленно ли обрабабатываются запросы и т.д.).
Скрипт, формирующий файл для zabbix_sender-а и запускающий zabbix_sender, может запускаться zabbix-агентом.
Для этого в конфигурационном файле агента zabbix_agentd.conf создадим ключ nginx_status:
UserParameter=nginx_status,/home/zabbix/nginx.sh 127.0.0.1
Содержимое /home/zabbix/nginx.sh примерно такое:
#!/bin/sh
# this script tries to collect nginx data
######################################### Active connections: 768 ## server accepts handled requests ## 133844 133844 601894 ## Reading: 63 Writing: 21 Waiting: 684 #########################################
WGET="/usr/local/bin/wget"
ZBX_STATS_FILE="/var/log/zabbix/ZabbixStats.txt"ZBX_SENDER="/home/zabbix/bin/zabbix_sender"ZBX_CONFIG="/home/zabbix/conf/zabbix_agentd.conf"ZBX_HOSTNAME=`grep "^Hostname" ${ZBX_CONFIG} | cut -f2 -d"="`
NGX_STATS_FILE="/var/log/zabbix/NginxStats.txt"if [ -z $1 ]; thenNGX_HOSTNAME="localhost"elseNGX_HOSTNAME="${1}"fi
$WGET -q -O ${NGX_STATS_FILE} -t3 -T5 http://${NGX_HOSTNAME}/nginx-status
if [ $? == 0 ]; thencat ${NGX_STATS_FILE} | awk -v myhost=$ZBX_HOSTNAME '/Active connections/ {active = int($NF)}/\W*([0-9]+)\W*([0-9]+)\W*([0-9]+)/ {accepts = int($1); handled = int($2); requests = int($3)}/Reading:/ {reading = int($2); writing = int($4); waiting = int($NF)}END {print myhost, "nginx_status.active", active;print myhost, "nginx_status.reading", reading;print myhost, "nginx_status.writing", writing;print myhost, "nginx_status.waiting", waiting;
print myhost, "nginx_status.accepts", accepts;print myhost, "nginx_status.handled", handled;print myhost, "nginx_status.requests", requests;}' > ${ZBX_STATS_FILE}
${ZBX_SENDER} -i ${ZBX_STATS_FILE} -c ${ZBX_CONFIG} >/dev/nullecho 1;exit 0elseecho "0"exit 1fi
При запросе сервером zabbix ключа nginx_status, скрипт вышлет данные серверу.
Создаем в zabbix-сервере шаблон - Template App Nginx.
Создаём в шаблоне элемент данных типа zabbix agent, запускающий скрипт /home/zabbix/nginx.sh (Рис. 1).
Рисунок. 1 Элемент данных, запускающий скрипт /home/zabbix/nginx.sh
Скрипт в случае успешного получения страницы nginx-status возвращает 1 и 0 - в противном случае. Полезно создать триггер отслеживающий эту ситуацию (Рис. 2).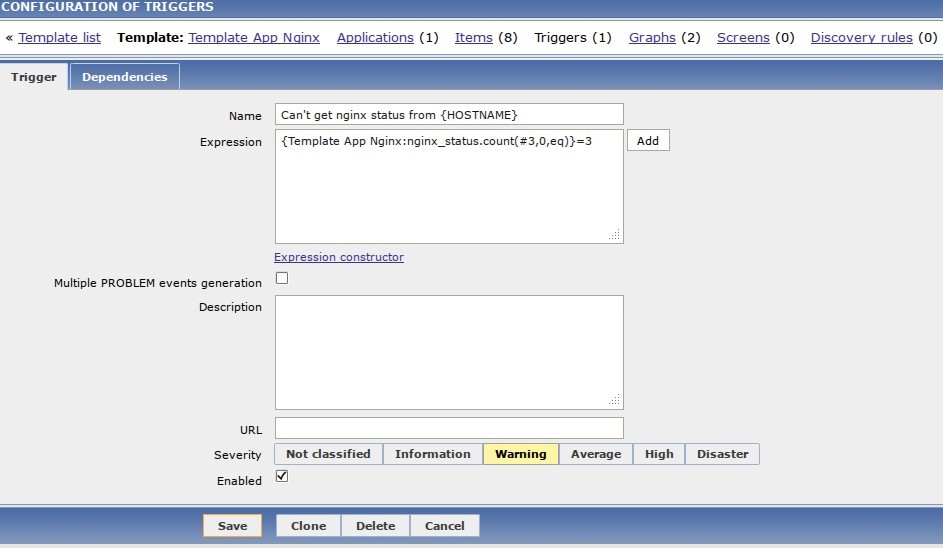
Рисунок 2. Тригер, отслеживаюший возможность получения статуса с Nginx.
Далее для каждого параметра создаем элемент данных типа zabbix trapper. На Рис.2 пример для метритки nginx active connections.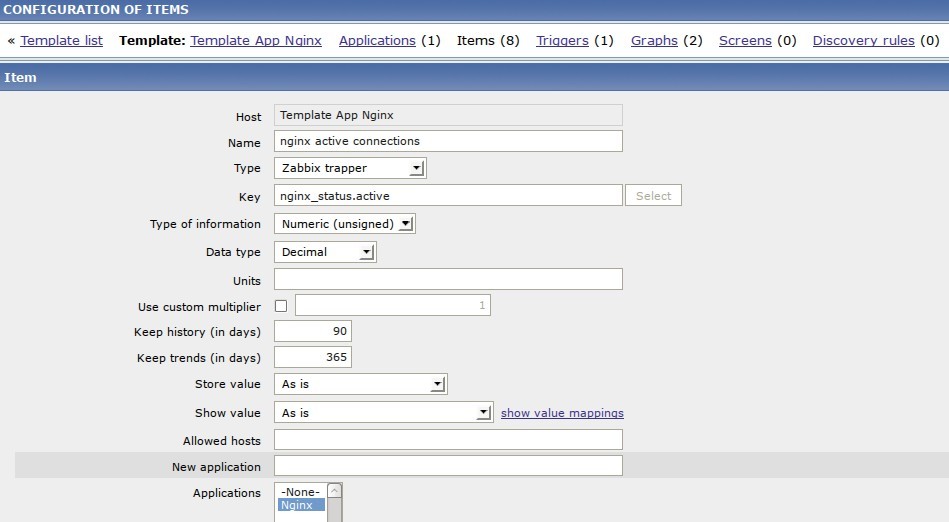
Рисунок 3. Создание элемента данных для метрики nginx active connections.
По аналогии делаем элементы для остальных метрик. Изменяется только название элемента данных (Name) и ключ (Key).
После объединения графиков в группы получаются графики как на Рис. 4 и Рис. 5.
Рисунок 4. Статус соединений.
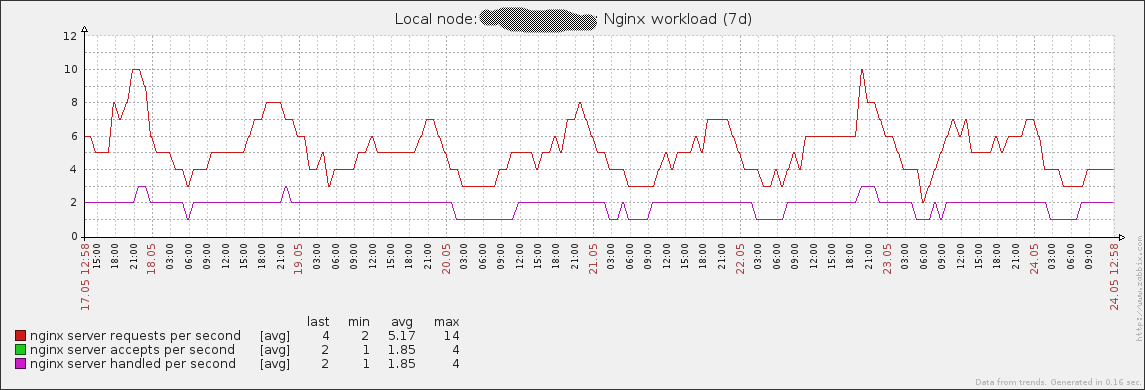
Рисунок 5. Нагрузка на сервер.
Шаблон для мониторинга nginx можно скачать отсюда: http://forum.itrm.ru/t/94/